Text Was a Problem Long Before AI
The overlooked history that explains why tokenisation exists at all
I remember watching The Imitation Game and feeling impressed in the way you are supposed to feel. There were brilliant people, impossible constraints, war-time urgency, and machines doing clever things. It felt important, but it also felt distant in a strange way, like I was admiring a story that belonged to another era and another kind of problem. At no point did it feel like a story about text. It did not feel like a story about the thing I spend most of my computing life doing: typing, reading, searching, asking questions, and receiving answers written in language.
Much later, I visited the Alan Turing memorial in Manchester, and I remember standing there longer than I expected to. I read the plaque. I looked at the statue. I watched other people walk past it with the quick glance you give to anything that is meaningful but not urgent. And while I stood there, something slightly uncomfortable started to surface. Not about intelligence. Not about learning. About something far more basic, almost embarrassingly basic once you notice it. I interact with computers constantly. I type messages. I read articles. I search documents. I ask machines questions and expect answers written in language. That expectation feels normal now. It feels like the natural shape of computing. But standing there, what began to bother me was the quiet assumption underneath it all: why did I ever assume that text naturally belongs inside a machine?

From the internet. I realised later that I am terrible at taking photos.
We talk today about language models, understanding, reasoning, intelligence. But all of that quietly assumes something much stranger underneath: that text can even enter a machine in the first place. That assumption is so deeply baked into modern computing that we rarely notice it. Text editors. Terminals. Browsers. Chat interfaces. Everything begins with text, so it feels fundamental, like it must have always been there. But it is not. Text is vague, contextual, deeply human. The same sentence can mean different things depending on who reads it, when they read it, and why. Machines, on the other hand, are rigid by design. They operate on exact states, exact transitions, exact rules. If you put these two worlds side by side—language as lived experience and machines as formal systems—there is no obvious meeting point between them. And that is what makes the present feel so strange once you slow down enough to notice it.
What a computer originally was
To see why text did not naturally belong inside machines, it helps to rewind the meaning of the word computer itself. For a long time, it had nothing to do with electronics, screens, or software. A computer was a person. Someone whose job was to compute. They sat with tables, notebooks, slide rules, and formulas, carefully and repeatedly turning mathematics into numbers by hand. The output was not explanation or insight. It was numbers. When machines finally appeared, they were built to take over exactly this task. Not thinking. Not understanding. Just computation. The goal was to remove human error and human fatigue from repetitive calculation. Nothing about their design assumed language. There was no expectation that a machine would ever need to read, write, or interpret words. That idea simply did not exist yet.
The world these machines were built for
The earliest electronic and electromechanical computers were born into a very specific environment. They were built for ballistics calculations, trajectory prediction, logistics planning, and later, weather modeling. These were problems that already lived comfortably inside mathematics. The inputs were numbers. The outputs were numbers. The value of the machine lay entirely in how quickly and reliably it could move from one to the other. There were no documents to process, no explanations to generate, no questions to answer. The surrounding world of these machines was not linguistic. It was quantitative. When we imagine early computers struggling with language, it is tempting to think of that as a limitation. But in context, language was not missing. It was irrelevant.

When you look at these machines, with their rooms of cables, glowing vacuum tubes, and mechanical relays, it becomes clear that this is not just about old technology. It is about a worldview. These systems were not built as general reasoning devices. They were built as engines for numerical transformation. Asking them to deal with text would have been like asking a calculator to understand a poem. Not because it was bad at poetry, but because poetry had no place in its universe. The machine was not built to hold ambiguity. Ambiguity was not just inconvenient. It was fatal. Everything had to be exact, measurable, and unambiguous, because the machine could only operate on what could be reduced to precise states.
Inside the machine
Inside these early machines, there were no letters waiting to be discovered. No words hiding beneath the surface. There were only states. Voltages moving through circuits. Switches being flipped. Counters incrementing and resetting. Everything the machine interacted with had to be exact, measurable, and unambiguous. From the machine’s point of view, the world consisted of operations like addition and subtraction, multiplication, conditional branching, and table lookups. That was the entire universe. Anything that mattered had to be expressed in that form. Anything that could not be expressed that way simply did not exist. If you had tried to hand one of these machines a paragraph of English, it would not have rejected it. It would not have misunderstood it. It would have no way to even recognise that you had provided input. Language did not fail inside early machines. Language never entered them in the first place.
This is the part that is easy to miss when looking backward from the present. Modern machines did not start out bad at language and slowly improve. They started out in a world where language did not exist at all. Text was not something they struggled with. It was something they were never designed to encounter. Language had to be forced into a system that only understood quantities. It had to be reshaped, compressed, and constrained until it could survive inside a numerical world. And that process did not begin with learning or intelligence. It began with a much simpler problem: how do you pass language through a system that does not understand language?
Language meets the wire
Humans had already faced this problem once before. Not with computers, but with wires. Long before computers ever existed, humans had already stumbled into the same constraint, not in laboratories, but stretched across distances. The telegraph made the question impossible to ignore. A wire does not know letters. It does not know words. It does not know meaning. All it knows how to do is carry electrical signals: on, off, pulse, silence. If language was going to travel through a wire, it would have to change first. Morse code was the first honest response to this constraint, not an attempt to teach the wire what language meant, but an acceptance that meaning would never live inside the system itself. Letters were stripped of their visual form and their sound. What remained were patterns of time: short signals, long signals, gaps. Dots and dashes were not chosen because they represented letters well. They were chosen because they survived noise. They could be detected reliably across distance. They could be reconstructed by a human on the other end. Meaning was removed at the source and reconstructed at the destination. The system never understood language. It only preserved structure well enough for humans to recover it.

Language survives only after being reduced to signals.
When every machine spoke its own dialect
By the time electronic computers became widespread, something important had already been settled without much debate. Humans had accepted that language would never enter machines as language. It would have to be reduced, encoded, stripped of everything that made it flexible or ambiguous. That lesson had been learned through wires, signals, and distance long before computers ever appeared. So when computers arrived, it felt reasonable to assume that the difficult part was over. Symbols could be represented as numbers. Numbers were exactly what machines were good at handling. From a distance, it looked like a clean handoff. Transmission had worked. Storage would work too. What nobody expected was that reduction alone would turn out to be the easy part.
Early computers did not enter a shared world of text. Each machine arrived with its own dialect, its own assumptions about how symbols should be represented. How many bits a character deserved. Which patterns mapped to which letters. What counted as valid and what did not. These choices were shaped by hardware limits and local convenience, not by any global plan. The result was a landscape of incompatible systems, where the same sequence of bits could represent different characters on different machines. A document created on one system might survive inside that system perfectly, and still collapse into something unrecognisable the moment it tried to move. This fragility was unsettling precisely because nothing was obviously broken. The machines were precise. The data was intact. The failure happened in the space between systems, where assumptions disagreed. For the first time, it became clear that text inside machines was not just a technical problem. It was a social one. Meaning was what failed to travel.
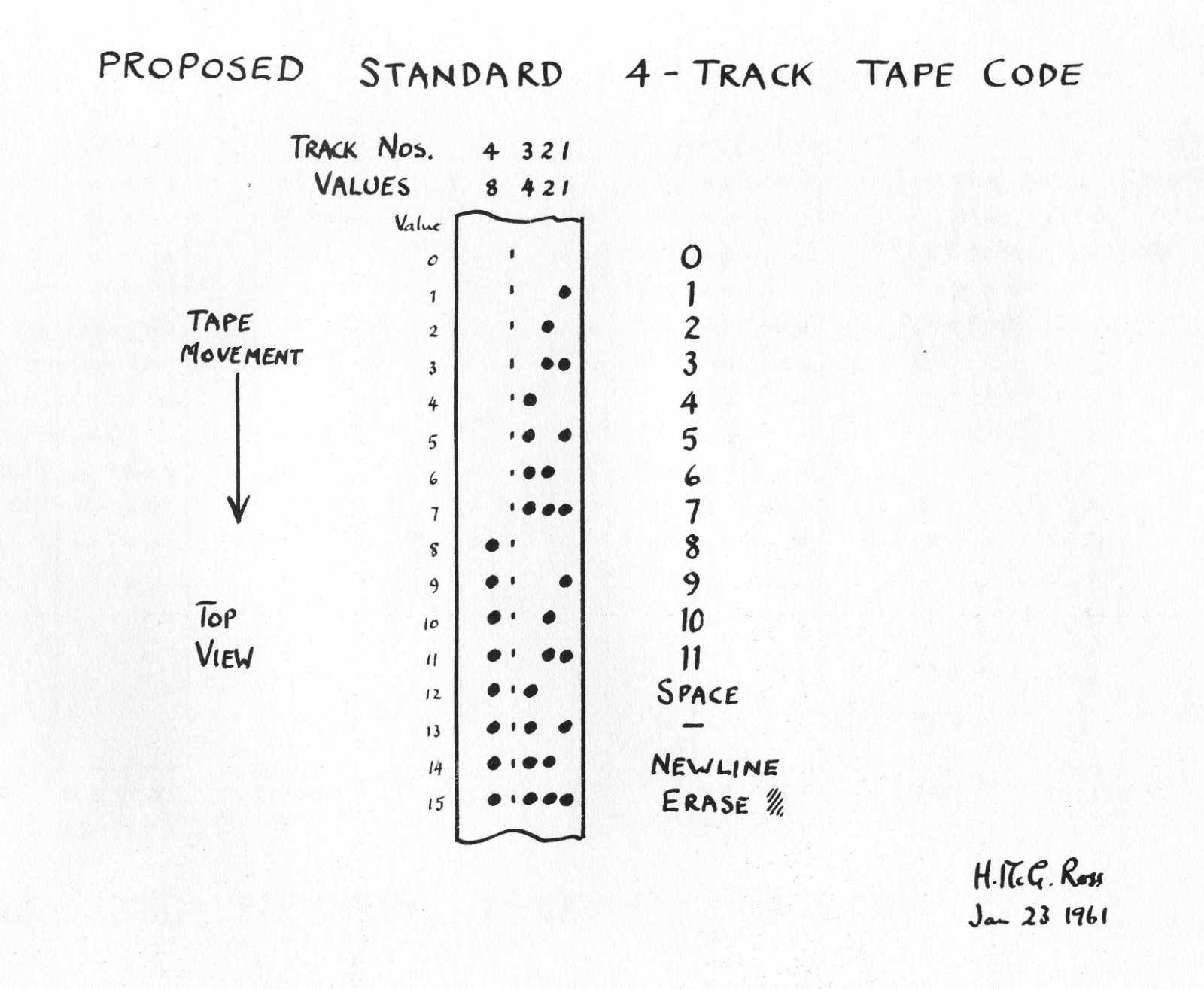
Text that could not survive migration.
Unicode and the promise of closure
ASCII did not emerge as a breakthrough in representation. It emerged as an act of coordination. Seven bits, one table, a small set of characters chosen not for richness but for agreement. It did not try to capture language in its fullness. It simply tried to make sure that when one machine said “A,” another machine would hear the same thing. What ASCII offered was not expressiveness, but alignment, and that was enough to make computing practical at scale. But as computing escaped its original cultural boundaries, the cracks became impossible to ignore. Different systems made different assumptions about encodings, about how many bytes represented a character, about where one symbol ended and the next began. The same stream of bytes could be interpreted in incompatible ways depending entirely on context, and once interpretation diverged, meaning collapsed into visual noise.
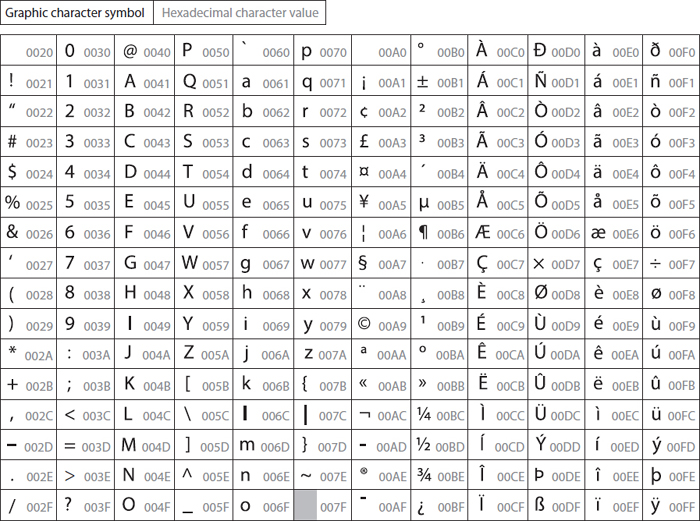
Unicode arrived as the attempt to end this uncertainty permanently. The idea behind it is deceptively simple: every character used by humans would be assigned a unique numerical identity that means the same thing everywhere, regardless of machine, operating system, or location. In many ways, this was extraordinary. Unicode solved a problem that had quietly haunted computing since its earliest days. Text could now be stored and transmitted at planetary scale without dissolving. But it is important to be precise about what Unicode solved and what it did not. Unicode assigns symbols numbers. It does not assign meaning. Two characters may be related in a language. They may form a word together. They may carry grammatical or semantic relationships. None of that exists in the code points themselves. From the machine’s perspective, Unicode characters are still isolated integers. They sit next to each other in memory, but they do not know why. Representation is stable. Structure is still absent.
When storing text was no longer the goal
This distinction is easy to miss because Unicode works so well. Text renders correctly. Documents survive transmission. Languages coexist peacefully inside machines. The system feels complete. And for a long time, that was enough, because most of what we wanted from computers was storage, transmission, and display. But the moment we started asking machines to learn from text, the nature of the problem changed. A learning system is not satisfied with preserving symbols. It is trying to discover patterns. It is trying to notice what repeats, what varies, and what tends to occur together. And at that moment, something that Unicode never promised to solve becomes impossible to ignore: Unicode gives machines symbols, but it gives them no guidance about structure.
Take three simple words: cat, car, and dog. To a human, these words do not feel equally related. Cat and car share letters, so they look similar. Cat and dog share meaning, so they feel conceptually close. But under Unicode, each character is just a number, so each word becomes a short sequence of integers. The only similarity that becomes immediately visible in that representation is surface form: cat and car share the same first two integers because they share the same first two letters. The relationship between cat and dog, which feels far more meaningful to us, is completely invisible at this level. If the representation highlights the wrong similarities, the learner will learn the wrong things first, not because the model is flawed, but because it is responding exactly to what it can see.
To eventually learn that cat and dog are related, the system has to observe many contexts and infer the connection indirectly, despite the representation giving it no help. This is possible, but inefficient, and it pushes the burden of discovering basic structure entirely onto the learning algorithm. In a sense, the model has to spend capacity rediscovering obvious units and relationships that humans take for granted, simply because the text has been presented to it in a form that makes the wrong structure look important.
Why tokenisation exists
This is the gap tokenisation fills. Tokenisation does not replace Unicode; Unicode still assigns numbers to symbols. Tokenisation sits on top of that and reorganises text into units that are useful for learning, not because they are the only correct units, but because they expose structure earlier. Instead of presenting a learner with a flat stream of characters, tokenisation tries to carve text into chunks that repeat, recombine, and carry statistical weight. Sometimes that means treating cat as a unit. Sometimes it means breaking rare words into parts that still contain signal. Sometimes it means reusing common fragments across many words so the model does not have to relearn the same patterns repeatedly. The goal is not to encode meaning directly, but to shape the learner’s view of text so that learning becomes efficient.
This is the first moment in the story where numbers are chosen deliberately to make learning easier, rather than simply to make text fit inside a machine. Once this shift happens, everything that follows in the modern language model pipeline starts to make sense, because the learner is no longer staring at raw symbols. It is staring at structure.
Comments